【MiraiNet】ローカルLLMの進化と実用性
こんにちは、技術部のエンドリューです。
ここ数週間で、小さめのコンピューターでも動かせる高性能なLLMモデルが数多く出てきます。
1か月前(2026年4月)にリリースされたAlibabaの最新モデル(Qwen3.6)は、2025年11月にリリースされたクラウド型の高性能モデル、Claude Opus 4.5に近い性能を出しました。
(画像のソース)
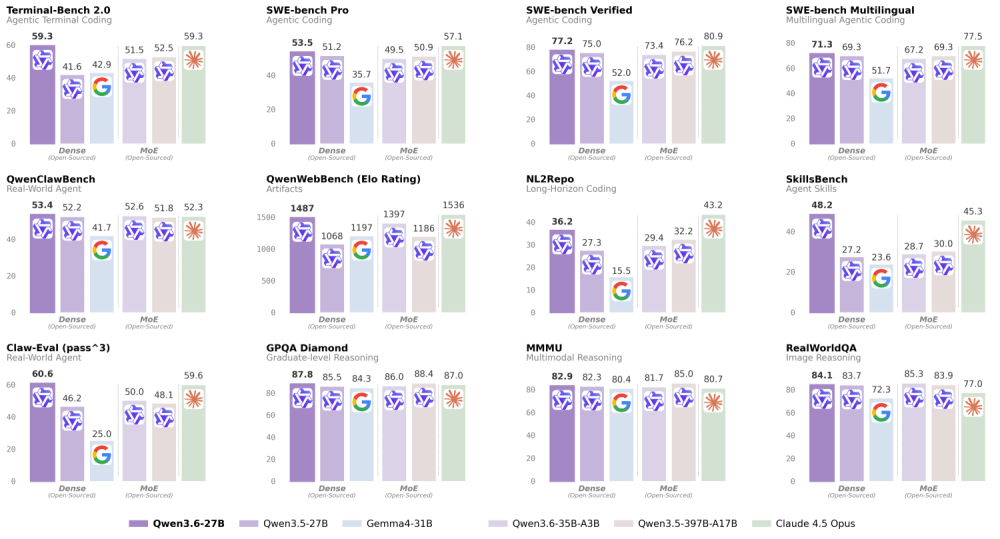
ローカルLLMモデルを選ぶときに重視すべきポイント
-
最近リリースされたモデルを選ぶ
ローカルLLMを使うときは、できるだけ新しいモデルや話題になっているモデルを選ぶのがおすすめです。HuggingFace(選択肢が多い)やOllama(使い始めやすい)で探すことができます。以下は、よく知られている提供元と最近のモデル例です。
- Meta: Llama 4
- DeepSeek: DeepSeek V4
- Alibaba: Qwen 3.6
- Google: Gemma 4
- Moonshot AI: Kimi K2.6
-
GPUのVRAMやユニファイドメモリに合うサイズを選ぶ
モデルのサイズが大きいほど性能は上がりやすいですが、その分メモリも多く必要になります。目安は以下の通りです。
モデルサイズ 標準(非量子化)の目安 4-bit量子化時の目安 7B-9B 14-18GB 6-8GB 12B-14B 24-28GB 10-12GB 32B-35B 64-70GB 20-24GB -
量子化(圧縮)
量子化されたモデルを選ぶと、品質をあまり落とさずにファイルサイズをかなり小さくできます。私はGGUF形式のファイルをおすすめします。llama.cppで簡単に動かせるからです(後ほど説明します)。
GGUFでは、Q4_K_M(4-bit quantization、K-Quants、medium size)がよくおすすめされています。品質とサイズのバランスが良いからです。16ビットのモデルを4ビットに圧縮しながら、精度の低下を小さく抑える方式です。
-
コンテキストウィンドウ
コンテキストウィンドウとは、モデルが1回のリクエストやチャットの中で読めるテキスト量のことです。たとえば、過去のチャット、アップロードしたファイル、長い文章などが含まれます。ChatGPT(GPT 5.5)、Google(Gemini 3.1 Pro)、Anthropic(Claude Opus 4.7)の高性能モデルは、どれも1Mのコンテキストウィンドウを持っています。最近の小さめのローカルLLMでも、256Kくらいのコンテキストウィンドウを持つものがあります。これだけあれば、中規模のソフトウェアリポジトリの情報も十分に扱えます。
ローカルLLMを動かす手順(llama.cppを使用)
-
llama.cppをインストールする
Macの場合は、Homebrewを使ってインストールできます。
brew install llama.cppWindows、Linuxの場合は、公式ドキュメント(英語)を参考にしてください。
-
リポジトリからモデルを探す
基本的にはHuggingFaceを使います。私はllama.cppで簡単に起動できるように、GGUFモデルを使っています。今回使うモデルは、gemma-4-E2B-it-Q4_K_M.ggufです。
-
Webサーバーとして起動する
llama.cppとダウンロードしたモデルを使って、ローカルのWebサーバーとして起動します。
llama-server -m ./gemma-4-E2B-it-Q4_K_M.gguf --port 8080 -ngl 99 -
GUIにアクセスする
ブラウザで http://localhost:8080を開きます。
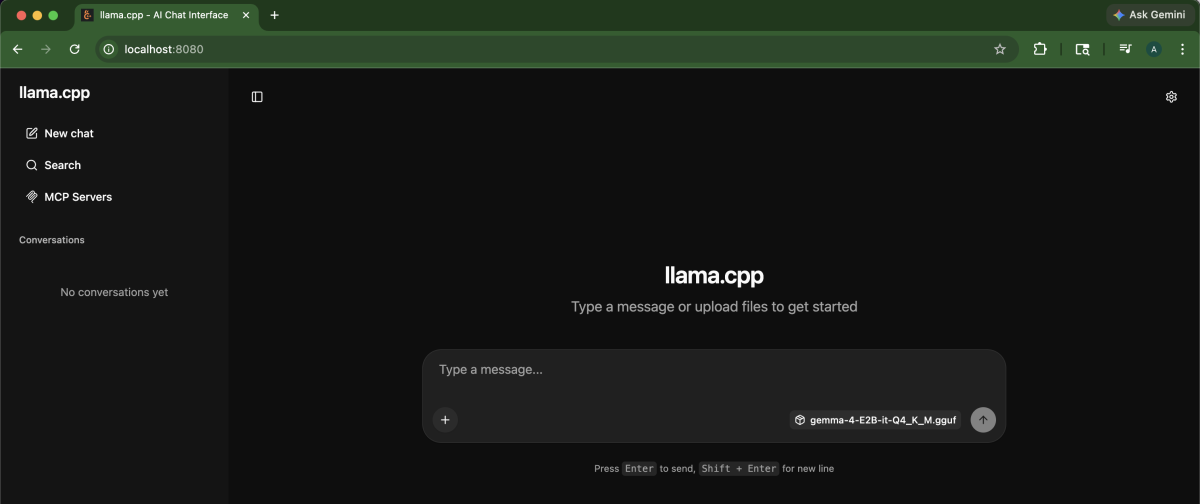
-
Pythonプログラムから利用する
Pythonプログラムで使う場合は、OpenAIライブラリがおすすめです。
from openai import OpenAI
client = OpenAI(
base_url="http://localhost:8080/v1",
api_key="API_KEY" #ライブラリではキーが必要ですが、サーバー側では無視されます
)
response = client.chat.completions.create(
model="local-model", #ライブラリではモデル名が必要ですが、サーバー側では無視されます
messages=[{"role": "user", "content": "Hello, how are you?"}]
)
print(response.choices[0].message.content)





